


Data Curation
YOUR TRAINING-TIME DATA SELECTION ENGINE
Big Data ≠ Big Information
After a series of AI Winters, Big Data acted as the single biggest accelerator to AI research: when data scientists are unhappy with their model’s performance, the first thing they do is try to get more data to help with model generalization.
The problem is, collecting and processing more isn’t cheap, and it’s time consuming too, and you are left managing large amounts of ROT data. Besides, the sad truth is that you’re not even guaranteed that it will make a significant difference, as not every record will contain information that’s both novel and relevant.
At Alectio, we believe it’s time for a paradigm shift from Big Data to Big Information. And that’s exactly what Data Curation will help you achieve: get better results, with less.


How does Data Curation work?

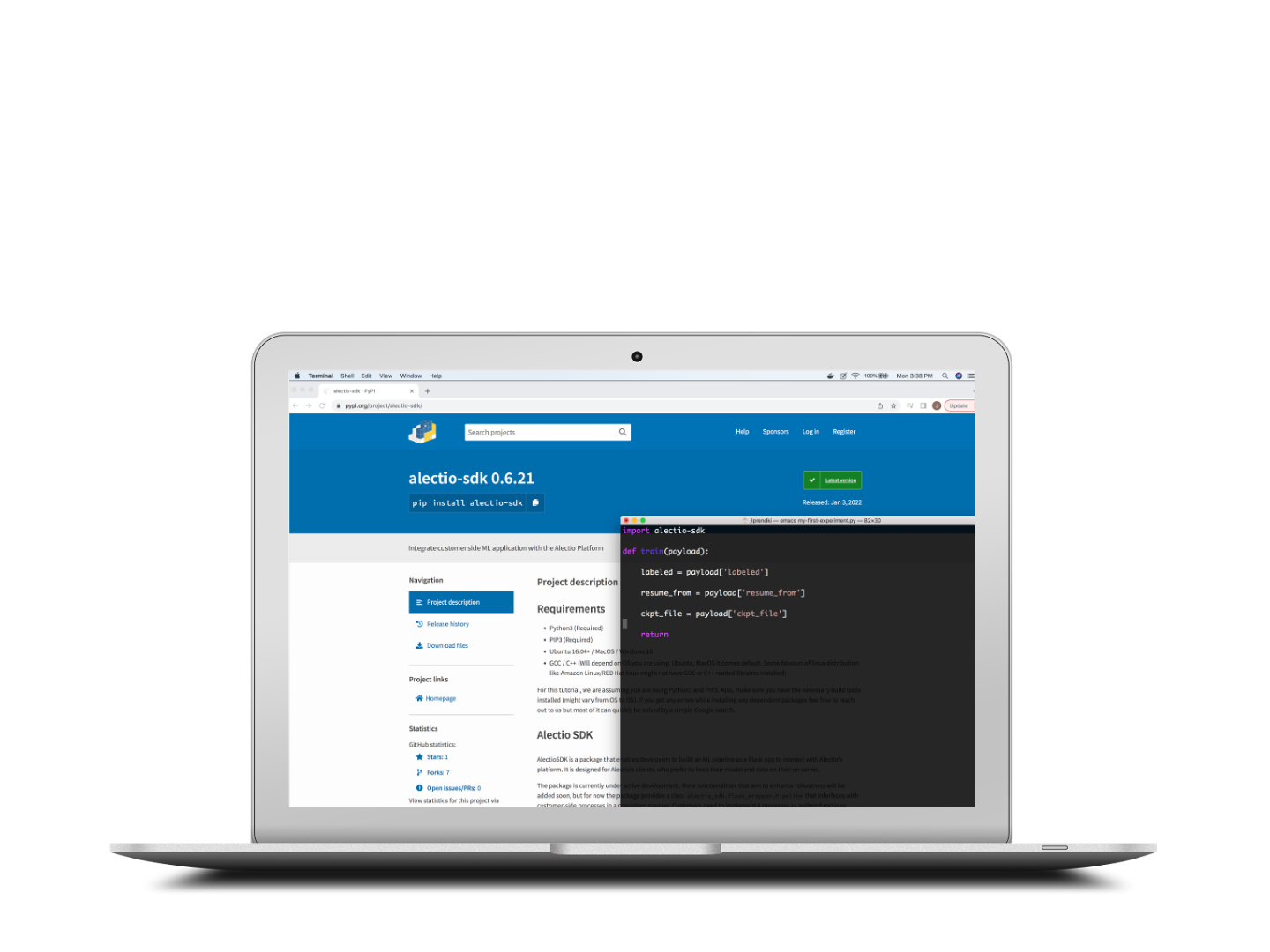
You setup the SDK
You set up the Alectio SDK on your system and let the SDK orchestrate an incremental training process for you. Your data and your model stay where they are; there is no need to export anything.
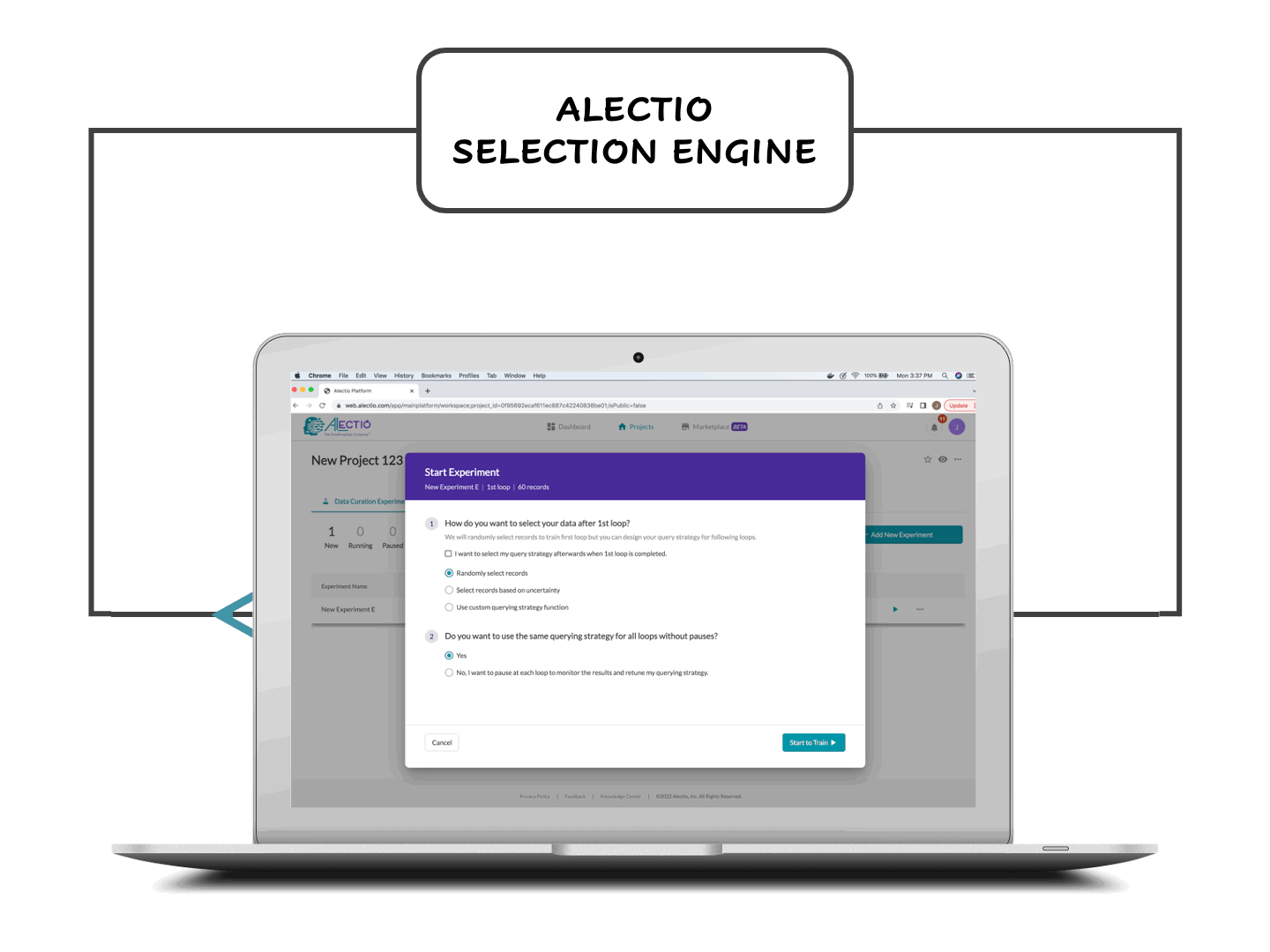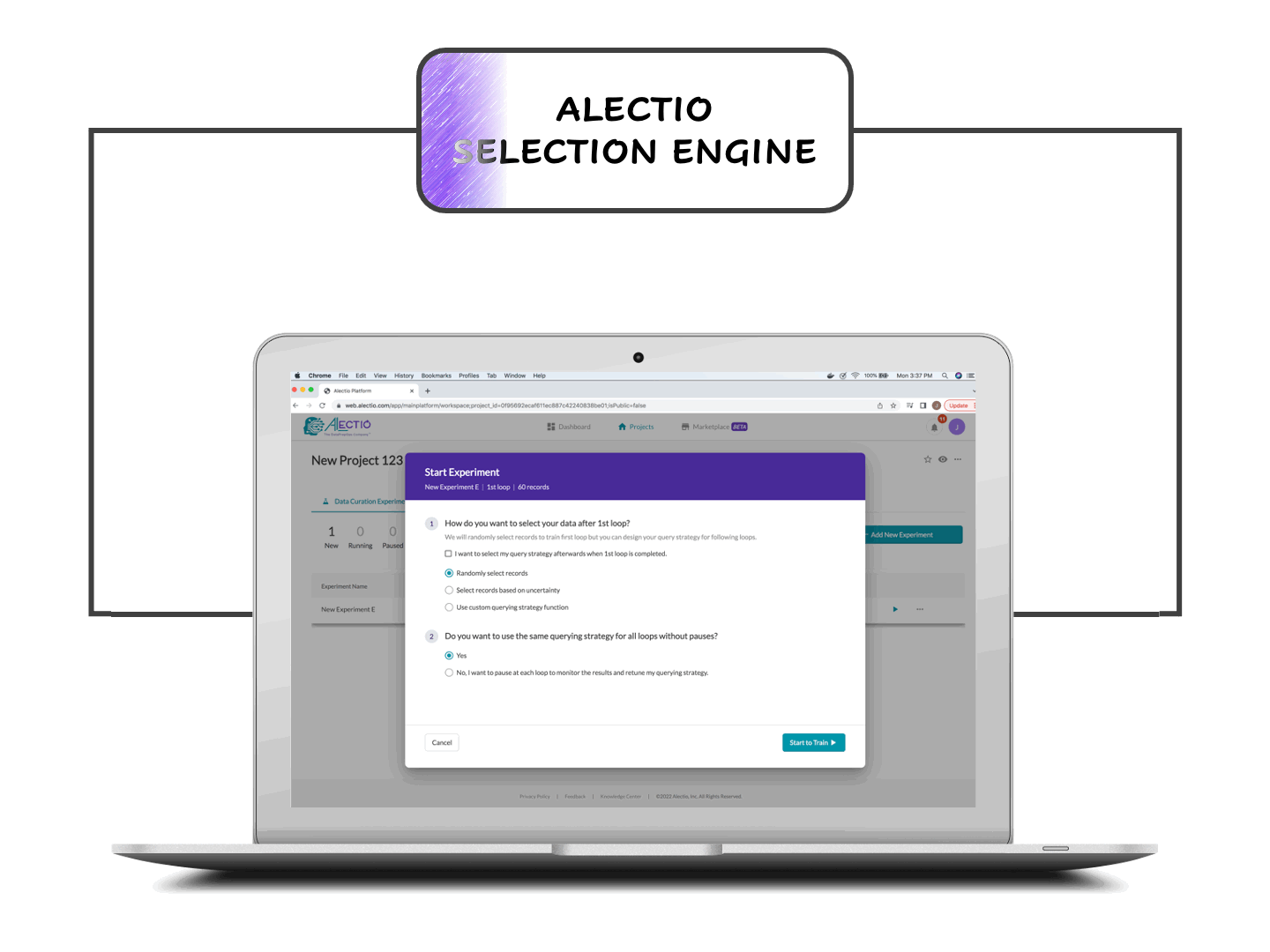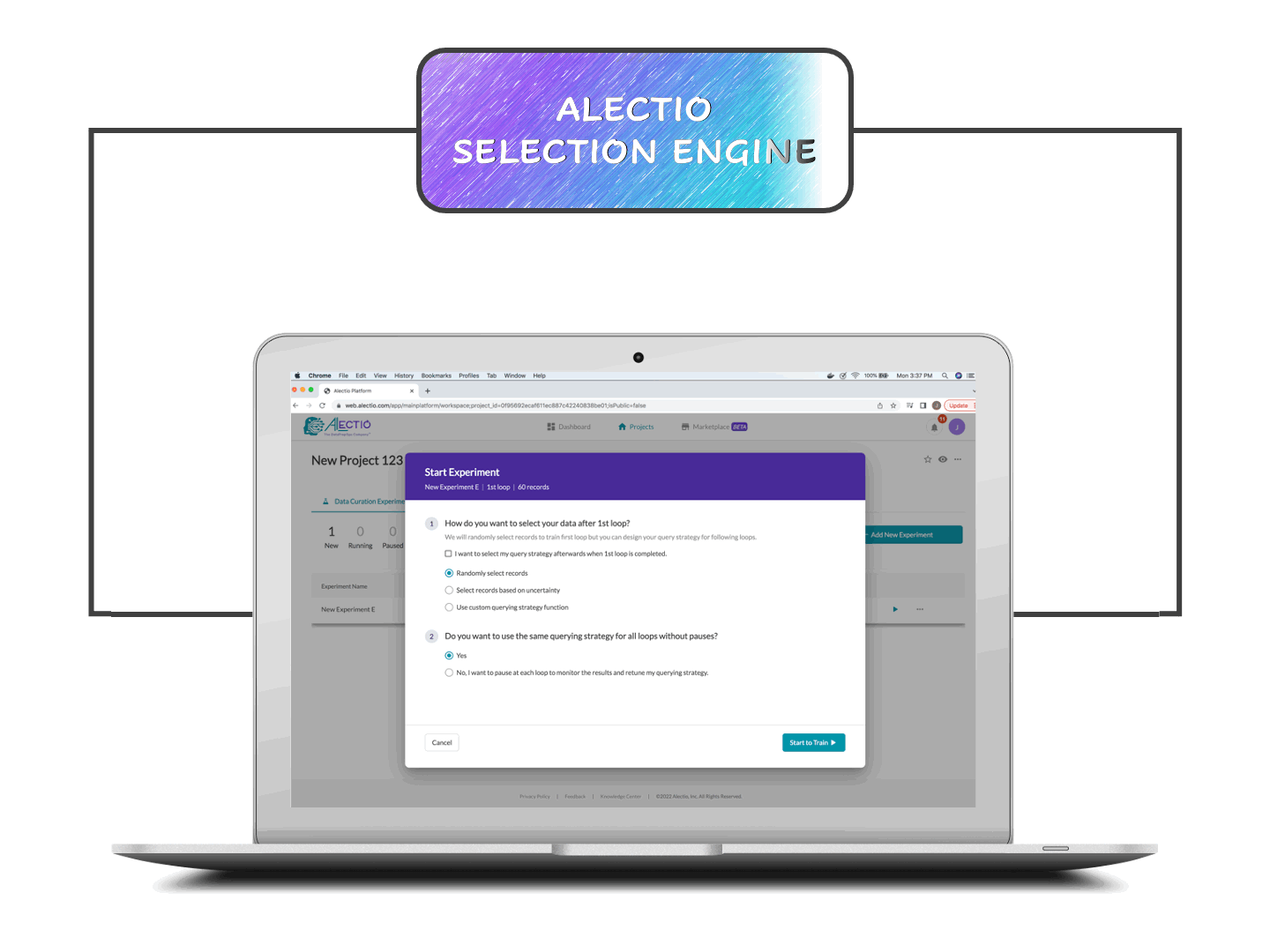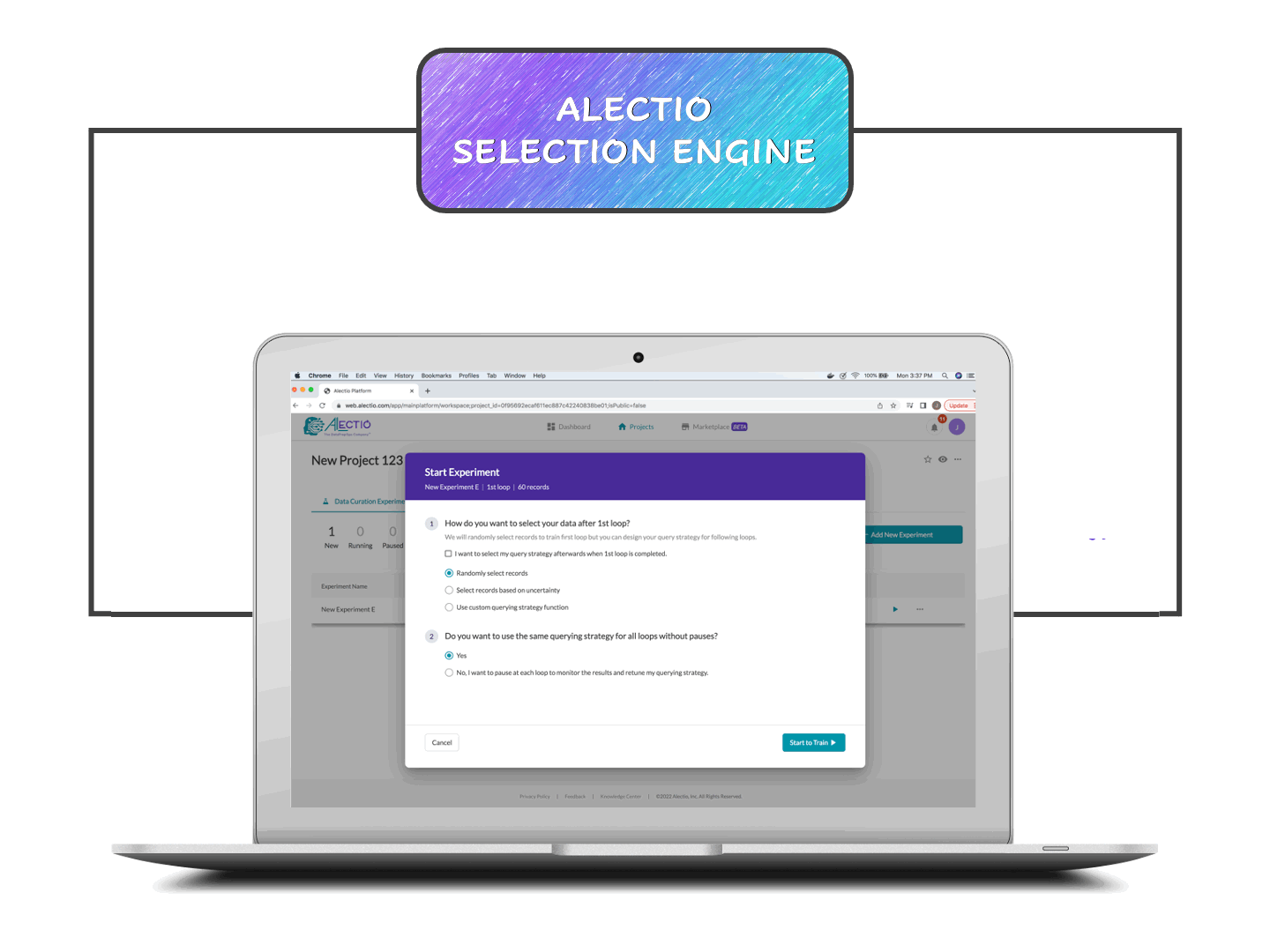
SDK orchestrates the training process
The SDK starts by injecting a small amount of data into the training process and captures clues about how things are going. That info is sent back to the Alectio engine which analyzes dynamically what works and what data will most benefit the training process next. If your data is unlabeled, you can use our hybrid labeling marketplace or your own provider to take care of it. Your model is trained incrementally with the most valuable data within your dataset.
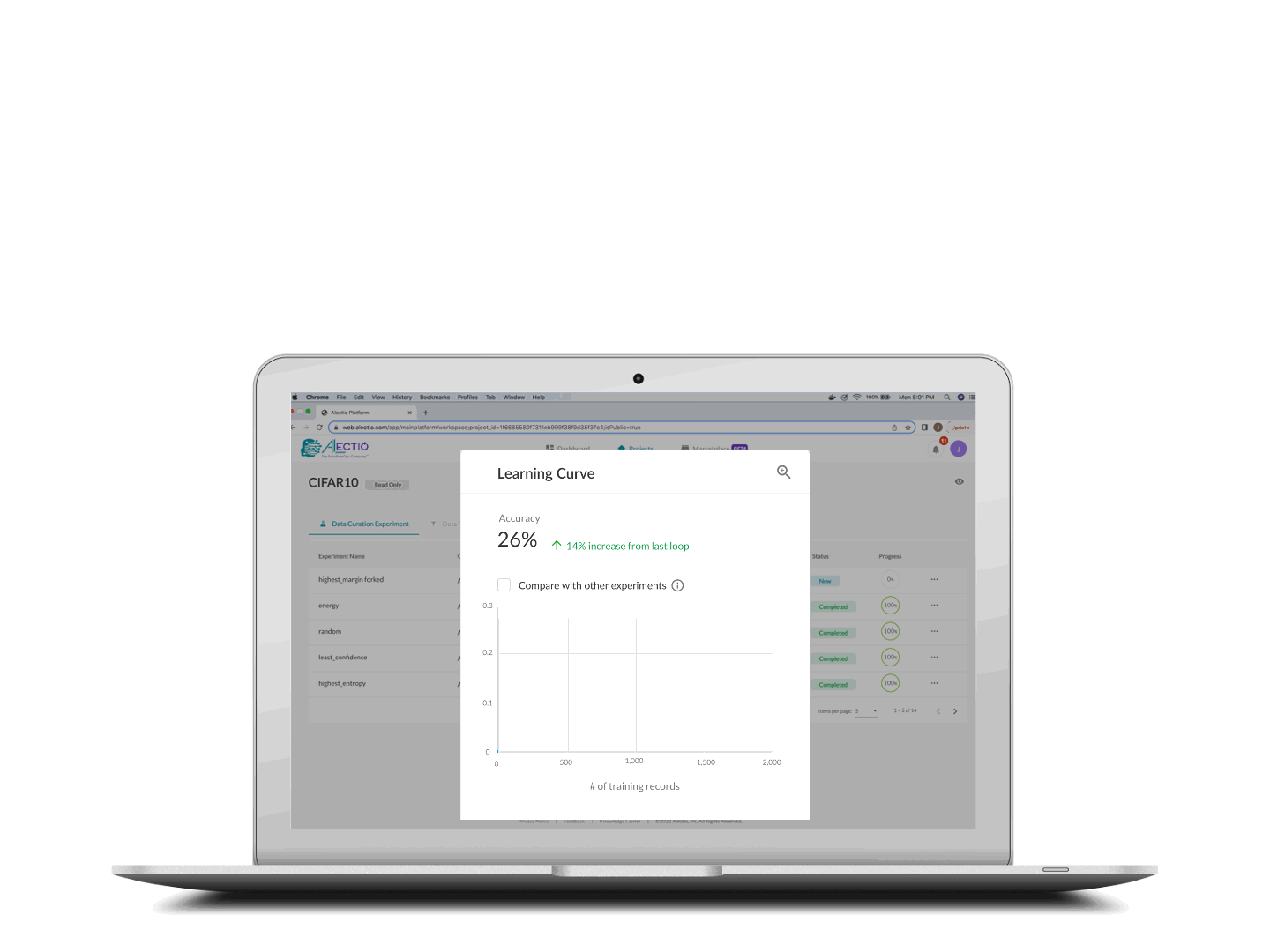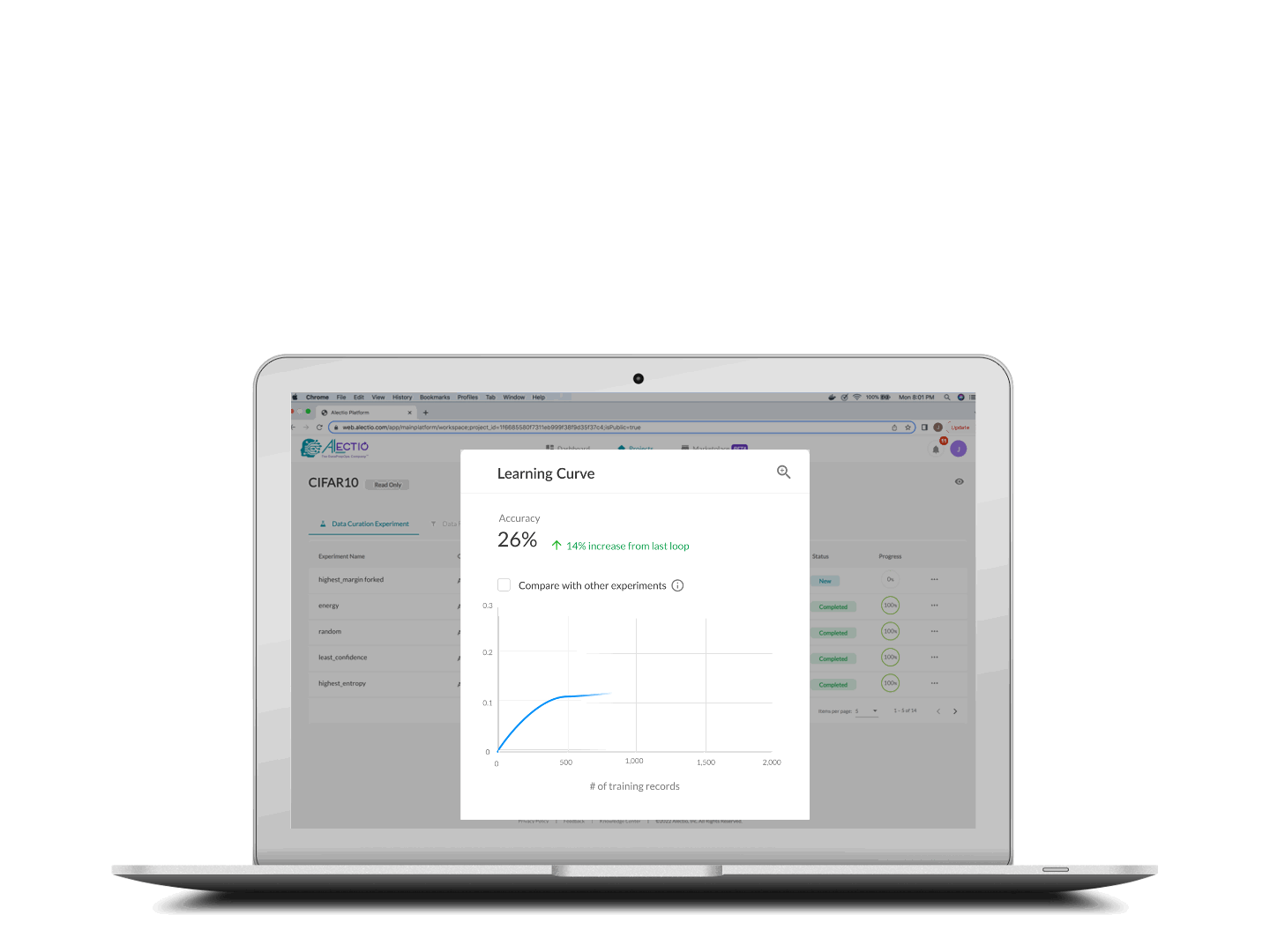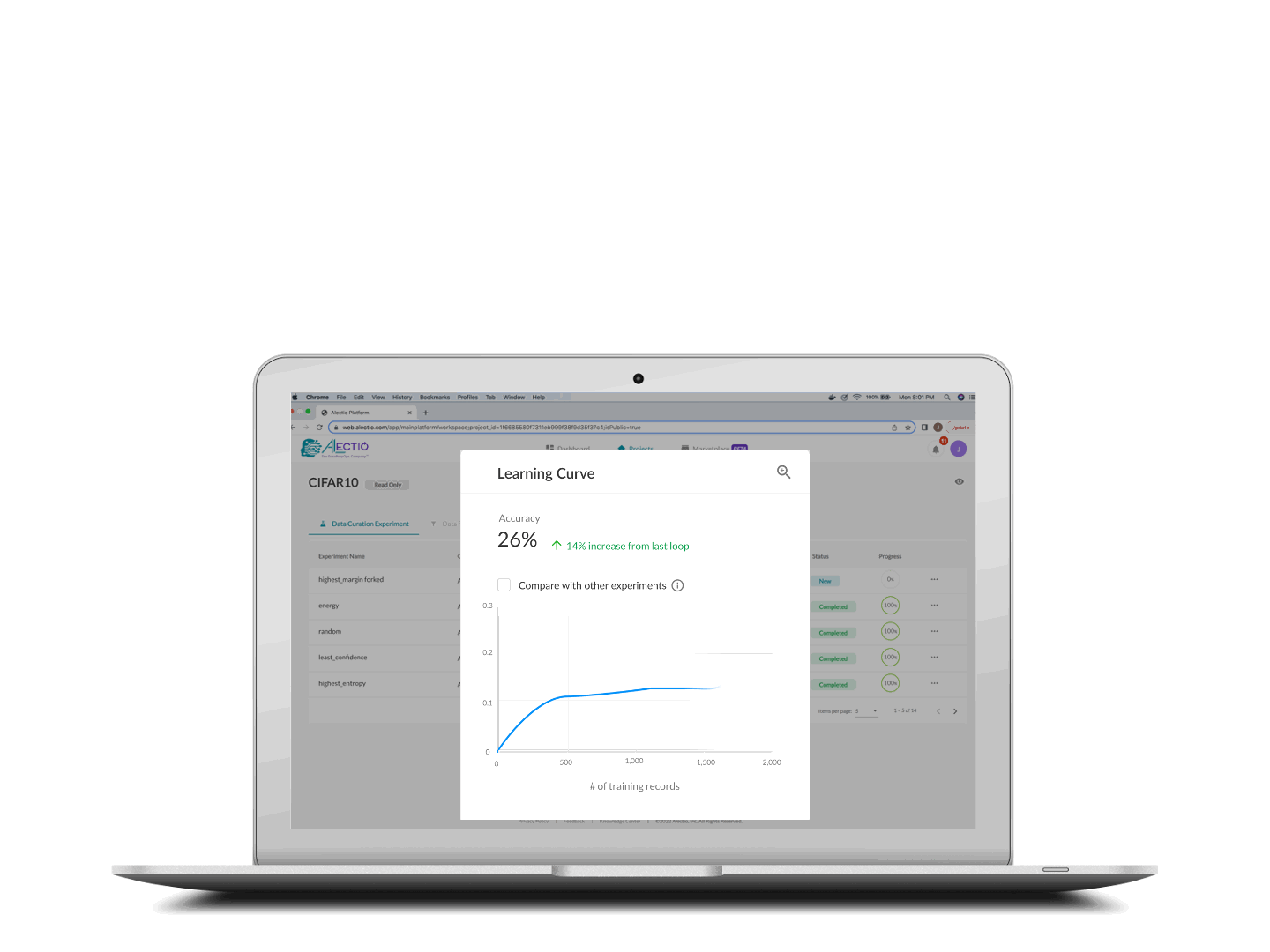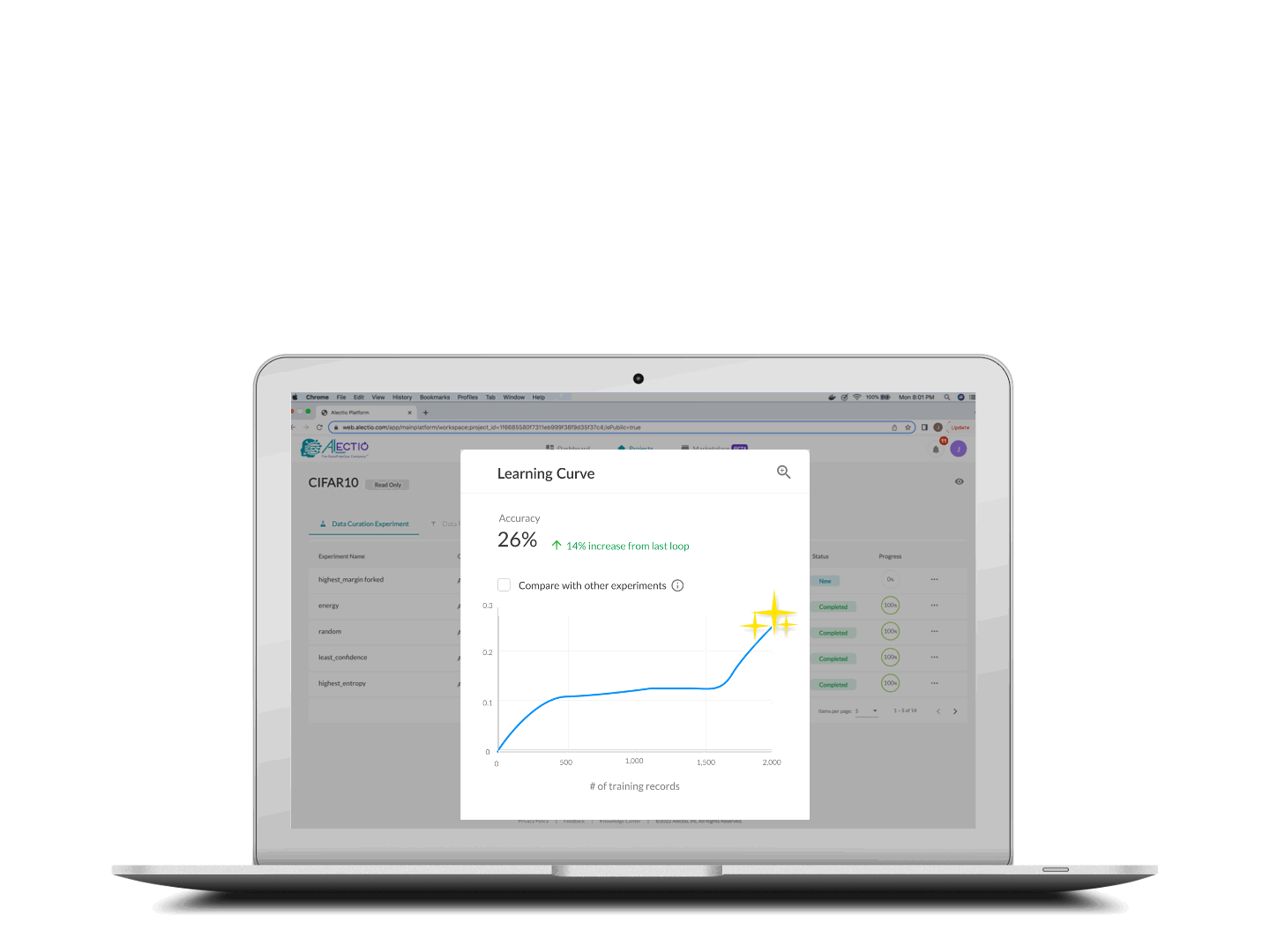
Training stops when your criteria is met
The training process stops either when you reach your budget (in time or money), or where the Alectio early-stopping technology identifies that the rest of the data contains no novel/relevant information.
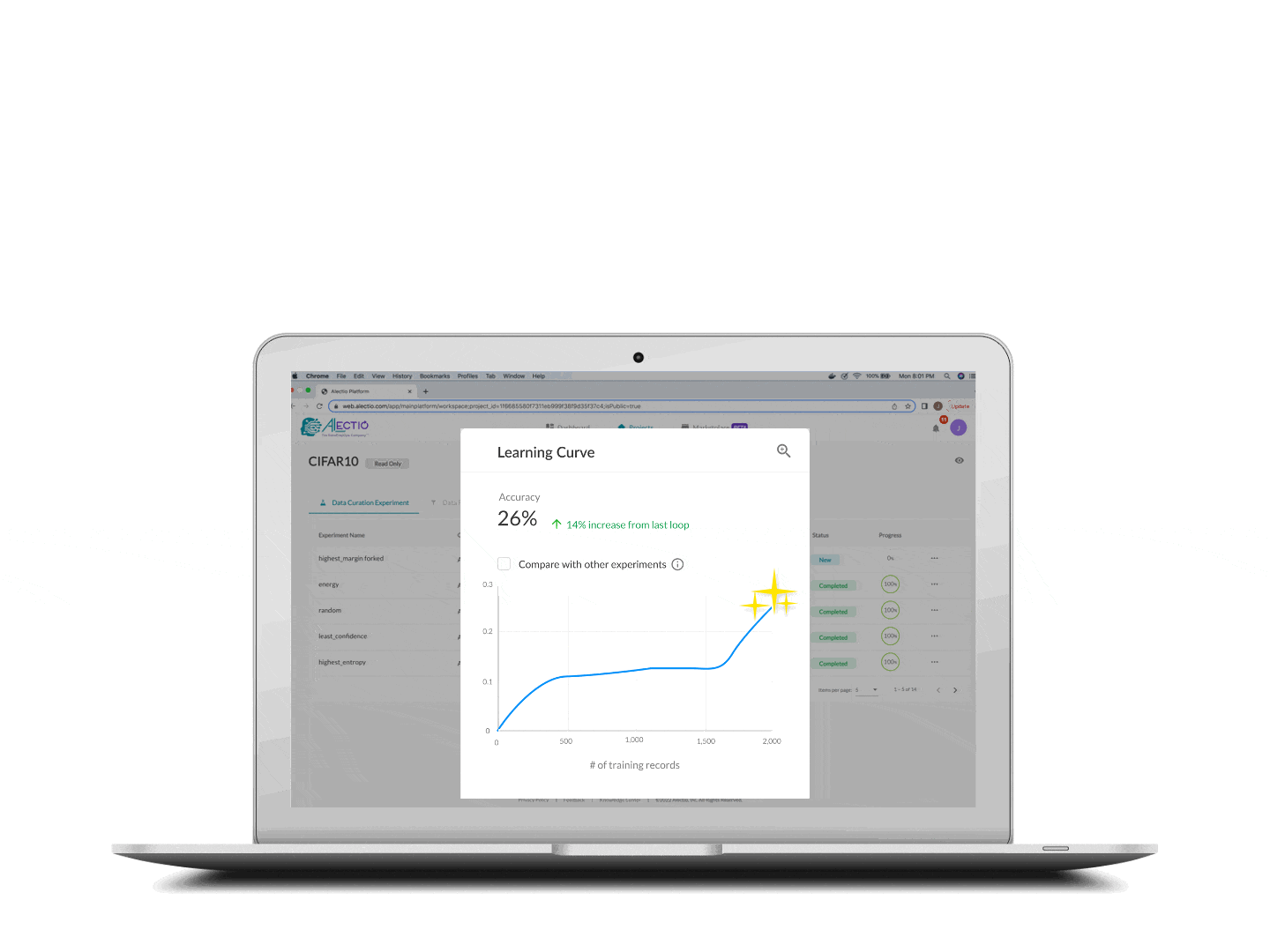
A smaller and optimized subset of data that is just right for your model
Your model gets trained with a smaller, optimized subset of data, allowing you to save time and money, and often to boost performance. You can also analyze what subset of the data was the most helpful and build a more strategic data collection/synthetic data generation process accordingly.
Next Generation Active Learning
Active Learning has long been known to academic researchers, but it is still misunderstood from data scientists because of how challenging it is to operationalize and tune with real-life data. Alectio is the ultimate Active Learning platform that solves all those challenges, making Data Curation accessible to experts and novices alike.
ML Pipeline for Active Learning
One of the reasons why Active Learning is hardly used in the industry is that iterative data pipelines are difficult to implement and maintain. With the Alectio SDK, you simply need to connect your model and your dataset and can enjoy the benefits of Active Learning immediately. You can even bring-your-own querying strategy if you want to!
Extensive querying strategy library with cards
Most people have heard of the least-confidence querying strategy, but did you know that there were countless more querying strategies that are often better suited than least confidence? The Alectio platform helps you find an off-the-shelf querying strategy that’s just right for you.
Human-in-the-Loop querying strategies
If you want to minimize the risk of overfitting or inducing catastrophic forgetting, this is the feature for you. Simply tune the learning rate of your Active Learning process manually by controlling the metadata distributions and complement your querying strategy with a stratified approach.
Machine-in-the-Loop Manual Curation
Sometimes, there is no replacement for human input, and it’s best to trust an expert to evaluate the usefulness of the data. If that’s your case, we have the solution for this, too: the system will pause at each loop and you’ll be shown records to select from along with relevant metadata to assist you in your decision.
Hybrid querying strategies
Querying strategies are often treated as static rules-based algorithms, but it often pays off to tune and modify the querying strategy throughout the process. The Alectio platform provides you with the flexibility (and the insights!) to do that and get a higher compression.
Querying strategy stabilizer
All Alectio querying strategies can be augmented with a patent-pending stabilization system relying on multi-gen metadata to avoid statistical fluctuations and overfitting. With this feature, you’re almost guaranteed that the performance of your model will not go down as you run more loops.
Auto Data Curation
No experience of Active Learning, but still want to curate your dataset? Don’t worry, this flagship Alectio offering makes that possible for you and automatically tunes the process thanks to its universal ML-driven selective sampling algorithm that thoroughly analyzes the training metadata in order to get the best dataset possible. just enter your criteria and let our technology do the rest.
Saving on Compute
Active Learning was originally invented to allow people to save on data labeling, but typically comes with a tradeoff in terms of computing resources because it requires retraining on the same records multiple times, across multiple loops. Compute-Saving Active Learning is the solution to this problem, and enables saving on compute as well.
Early Stopping
Set up your curation process so that training stops either when you reach your initial goal, run out of resources or when no new information can be found in your datasets. You won’t need to run more loops to realize that you have reached model saturation.
Early Abort
Historically, about 10% of all Active Learning processes fail because of bad luck at initialization. If this happens to you, the Alectio system will automatically identify the issue at an early stage and will reboot and reinitialize, avoiding you to waste precious time and computing resources
Active Knowledge Transfer [Coming soon]
Set up your curation process so that training stops either when you reach your initial goal, run out of resources or when no new information can be found in your datasets. You won’t need to run more loops to realize that you have reached model saturation.
Curation Report
Active Learning might be mainly a data selection process built to reduce the amount of data used to train a model, but it is actually a process to rank data by order of importance to the model. As such, it can be leveraged as an explainability tool to identify model weaknesses and understand the way information is transferred from raw data into the model.
Diagnostics model issues
The curation experiment report provides a large range of various graphs and metrics which you can leverage to analyze the weaknesses of your model and prevent overfitting.

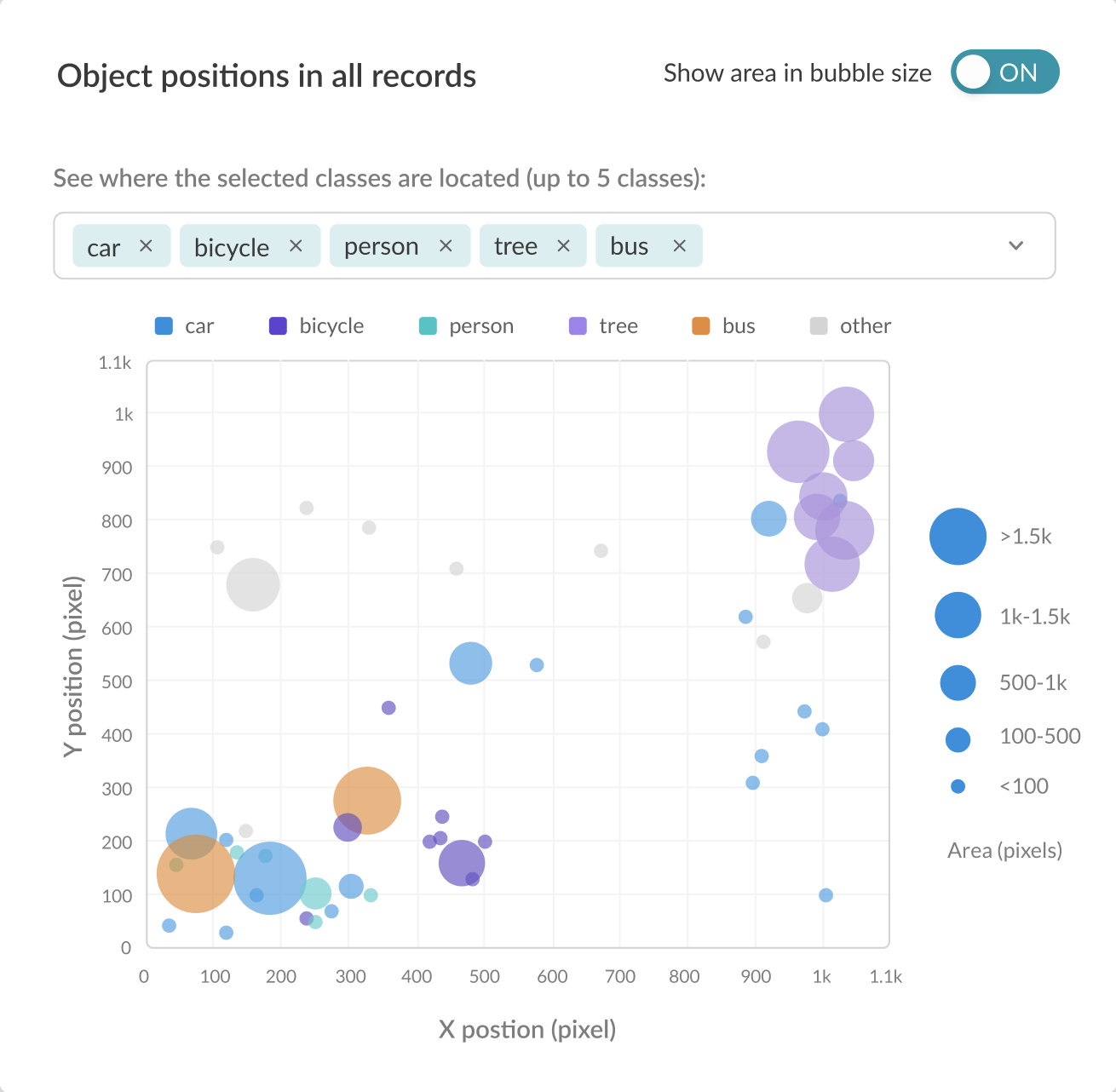

Training-Time Explainability Framework
Some of the graphs found under the labeling report are there to help you correlate the informational content of the useful records within your data and its impact on model training. This is information that you can use to develop smart data collection strategies, to guide a synthetic data generation process, decide which augmentations to apply on your data or as a more general explainability framework.
Advanced Tools [coming soon]
Alectio is providing a full suite of product features designed to do Data-Centric AI efficiently.
Stress Testing Tool
This tool is here to help you with project budgeting. It is designed to help you evaluate the quantity of training data and the maximum tolerated labeling inaccuracy in order to achieve your desired model performance before you start training your model.
Smart Data Collection Strategy Generator
This tool will give you the insights you need to start collecting your data strategically. Stop collecting data in a brute-force fashion, and start collecting information-dense data to save time and money.
Data Augmentation Insight Generator
Don’t waste your time analyzing your report to decide what augmentations to apply on your dataset: you’ll receive a list of recommendations in plain English to know what to do.
Smart Orchestrator for Synthetic Data Generation
If you already have a synthetic data generation process, but are not sure what exactly you should synthesize, this is the tool for you. Just plug your data gen API to the Smart Orchestrator to obtain a feedback loop designed to generate just the right data for your model.
STAY IN TOUCH
Want to keep up with what we’re doing? Sign up for our monthly newsletter: