


An Intro to Data-Centric AI
The history behind Data-Centric AI
The term Data-Centric AI was first coined by Computer Scientist Andrew Ng in 2021, but its story start long before, with other Machine Learning leaders like Fei-Fei Li, Andrej Karpathy, Robert Munro and Jennifer Prendki shaping its precepts as part of their own work.
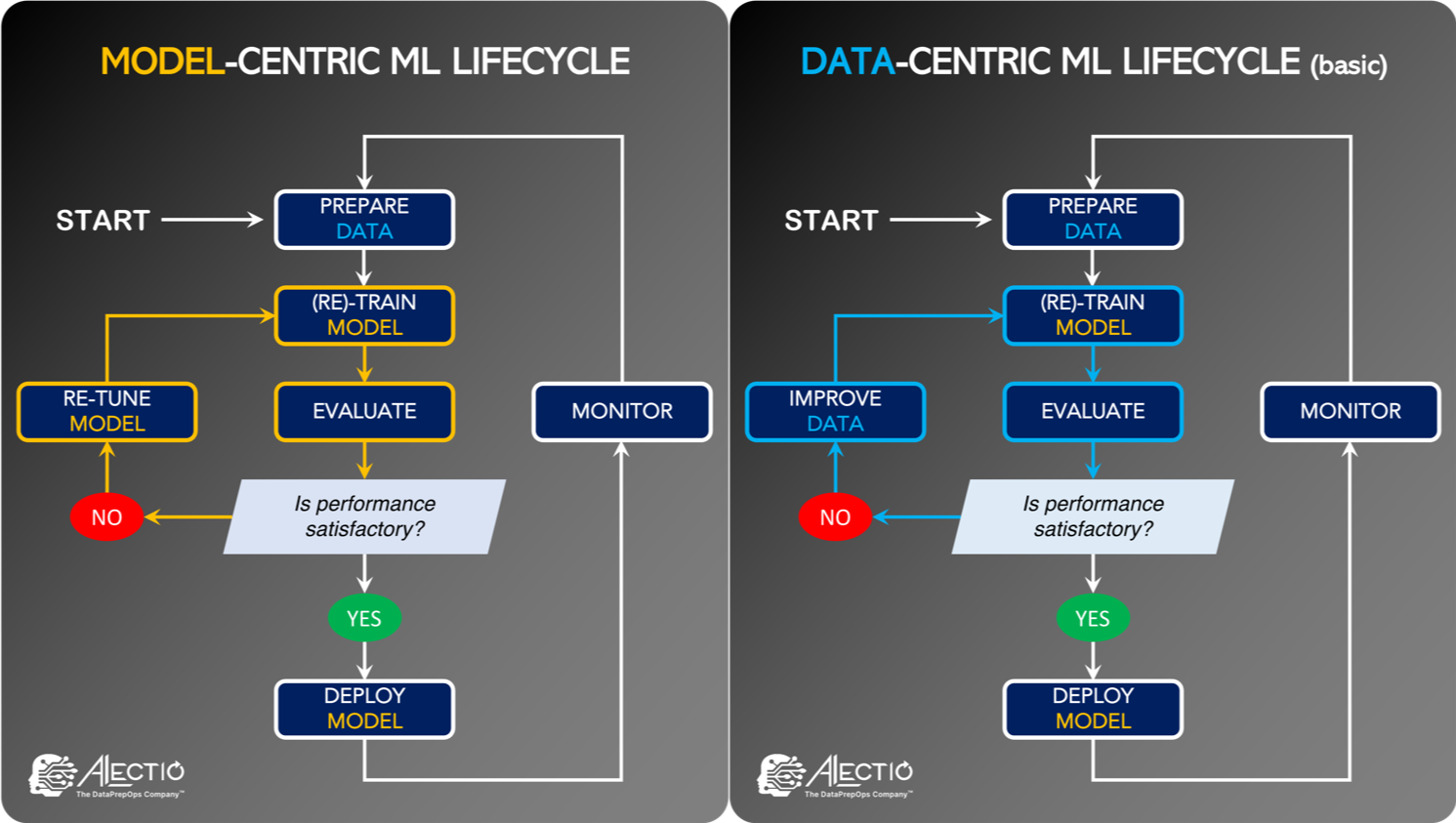
The idea behind Data-Centric AI is simple yet powerful: after decades of focus on the algorithms, it is time to put more emphasis on the data itself; in short, it’s about optimizing the data to the model, rather than the model to the data. This shift in paradigm shouldn’t come a a surprise as most data scientists have experienced first hand how critical data quality was in Machine Learning. Garbage In, Garbage Out, as they say. Data-Centric AI simply formalizes and brings a more formal framework to this concept.
Why is this shift in paradigm happening now?
The history of Machine Learning, and DeepLearning in particular were a bit bumpy and punctuated by AI Winters because the hardware necessary to collect and process large amounts of data was not invented or mainstream yet. As a result, ML researchers could only focus on the theoretical side of things, by developing algorithms, without being able to put their knowledge into practice.
It is only in the 2010s that hardware finally caught up with the needs of the ML Community, so most researchers are still used to the old way of thinking, so they tend to brute-force data into their models. It will most likely take a couple more years for Data-Centric AI to be fully adopted and taught in Universities and online courses.
Data scientists always spent lots of time on their data, what’s different here?
Building a training dataset does indeed take a lot of time, and to most data scientists, it is a necessary evil. What Data-Centric AI advocates, is to make Data Preparation part of the model building phase itself, instead of just considering it a preprocessing step, and to make it less manual and handwavy and more tech-driven and scientific along the way. The idea behind is that training data should work with the model, not against it.
How will Data-Centric AI impact ML Community as a field?
More research focus is definitely needed to develop algorithms, best practices and techniques to ‘tune’ data strategically, so it is to be expected that more ML experts will get involved in the field of Data-Centric AI. That said, as the discipline mature over the next couple of years, those new techniques will become more mainstream and open-source libraries will become available, so the daily lives of most ML practitioners won’t be much different from what it is today when they invoke a method in Scikit Learn or PyTorch.
What does Data-Centric AI imply in terms of ML Engineering?
Model-centric ML pipelines tend to treat data as a static object, so much so that most companies don’t even bother creating a data pipeline for Data Labeling (that means that most data scientists rely on email communication to get their data annotated by third-parties!). Since Data-centricity implies that data might have to be modified continuously, the traditional ML pipelines need to be fitted with systems and workflows that can support the monitoring, management and versioning of both training and streaming data. This is the topic of a growing field we call DataPrepOps, which includes specialties like Data Observability, Synthetic Data Generation, Autolabeling and Weak Supervision.
Improving data by modifying the labels
Data scientists have acknowledged all along that the quality of a training dataset is critically dependent on the quality of its labels. The issue though is that labeling large-scale data is insanely expensive, time-consuming and error prone. Under certain conditions, it is possible to rely on a pre-trained Machine Learning model or a weakly supervised approach to generate labels faster, but those techniques do little to guarantee the accuracy of the labels.
Human-in-the-Loop Data Labeling – a technique where a human agent identifies and fixes labeling errors and imperfections – is one of the most promising ways to address this. That said, much research is still needed to automatically identify problematic labels.


Improve data by modifying an existing dataset
Selecting data records from an existing raw dataset is one of the most natural ways to do Data-Centric AI: that’s what Active Learning is all about. That said, even though Active Learning isn’t exactly novel, it is still relying on very rudimentary selective sampling techniques which should be replaced by Machine Learning algorithms for better results (learn how we do that by visiting our Active Learning page).
At Alectio, we are also pioneering the usage of Active Learning as a technique to decide what records are harmful and to be removed from a dataset, or those that should be augmented (we can even advise what data augmentation technique should be applied!).
Improve data by collecting or generating new data
While this might seem obvious, another way to improve a dataset is to add more data, preferably in a strategic manner. Guiding the collection or the generation of new data in the way that it positively impacts the learning process of the model and makes it more efficient is a topic that sadly doesn’t get enough attention from researchers.
At Alectio, we are working actively on developing new techniques to guide our users into collecting more impactful data, either by providing general insights to improve data collection (we call that Strategic Data Collection), by guiding the generation of synthetic data (that’s Active Synthetic Data Generation) or by deciding at the point of collection which records to keep (this is a patent-pending technology we refer to as Data Filtering).