
A Primer

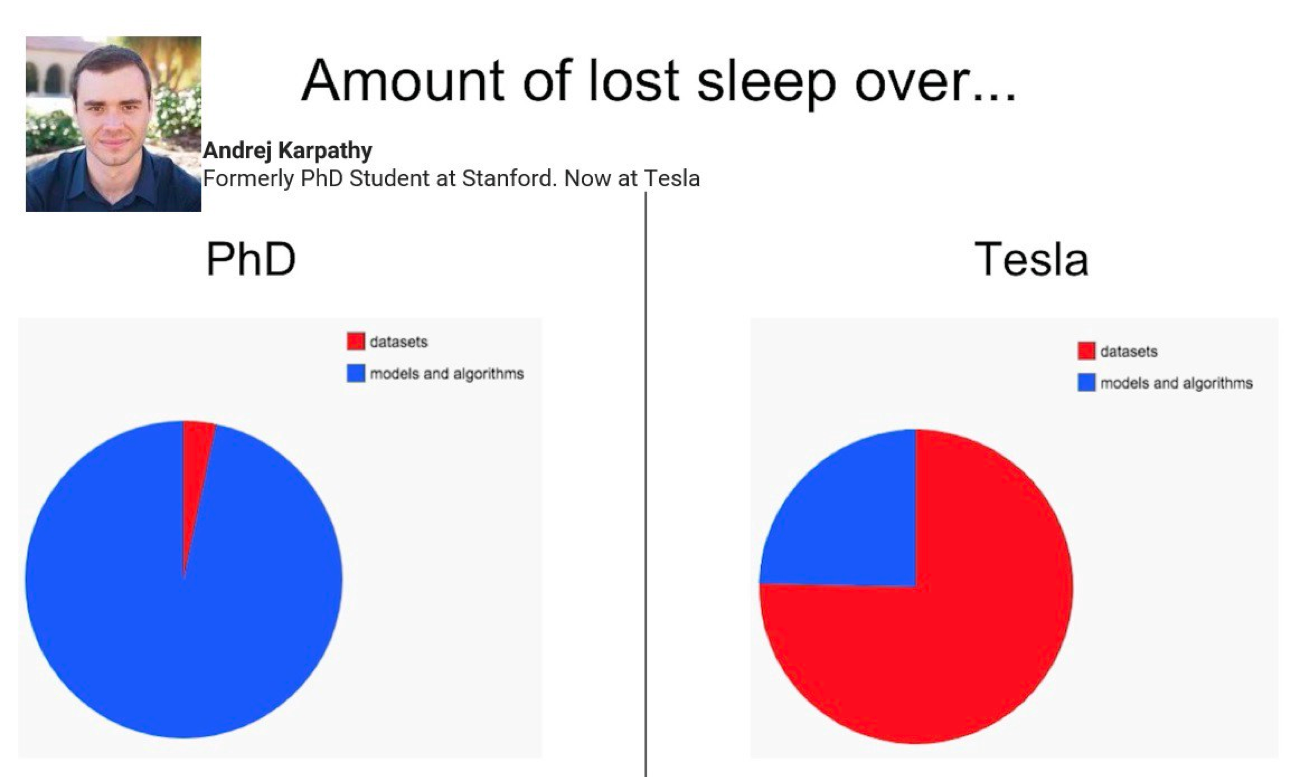
San Francisco, CA, May 2018: as the Train AI conference was drawing to a close, the audience was gathering one last time for what was one of the most anticipated talks of the day: Andrej Karpathy, Director of AI at Tesla. The talk begins on a light note, as Karpathy shares the results of an experiment carried by a group of Youtubers to test the limits of Tesla’s auto wiper system, and within minutes, he’s got his attendees wrapped around his little finger. That’s when things got more serious: Karpathy soon jumped into a technical conversation about the applications of Computer Vision at the company, and how getting a system to wipe off ketchup was not so much about model – it was all about the data.
Now, Karpathy was hardly in an adversarial situation: he was speaking in front of an audience made mostly of customers of the leading labeling company at the time. All of whom were like him; they knew that a high-quality training dataset was crucial to building killer models. So no eyebrows were raised when he pulled up his paramount slide illustrating how in practice, he would get a better return on investment on his time by perfecting his data rather than his model. Yet, this slide, along with the content of several other leading ML voices, such as Ruchir Puri, Chief Scientist at IBM, Andrew Ng, Professor at Stanford, Robert Munro, author of Human-in-the-Loop Machine Learning and then CTO of Figure Eight, and Jennifer Prendki, Alectio’s founder, would end up a conversation-starter in many ML circles for years to come, eventually leading to what is known today as the Data-Centric AI movement.
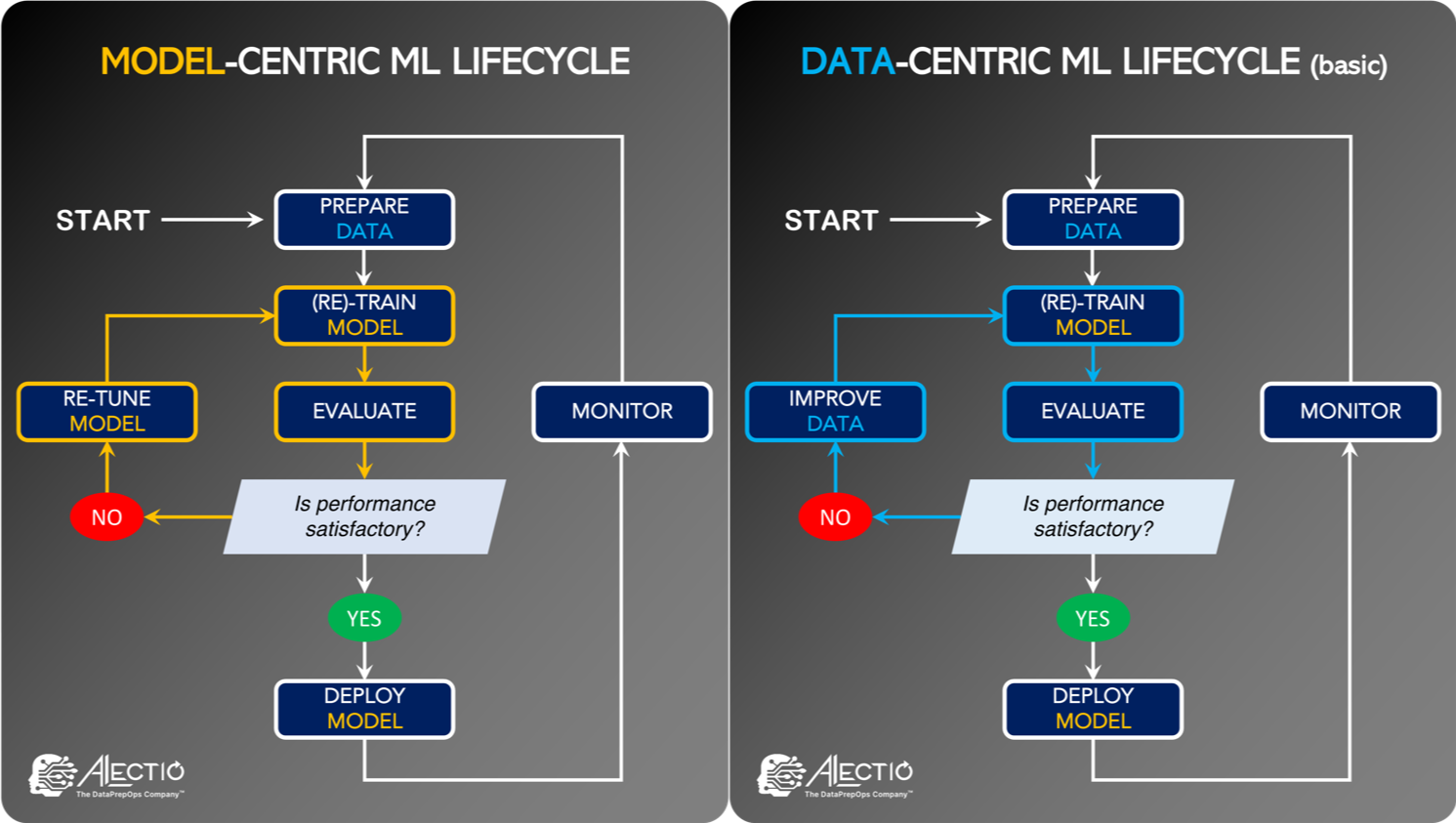
Data-Centric AI originated with the belief that the ML community should shift their focus from model building and tuning, to the data itself. But, it is much more than a mere philosophy. It is a brand new way to think about Machine Learning, and it puts data at the very heart of the ML lifecycle:
- With a Model-Centric approach (the “old way of doing ML”), the data scientist would try to improve the performance of their model by tweaking the model itself. This could include hyperparameter tuning, modifications to the model architecture, or changes in the type of algorithm.
- With a Data-Centric approach, the data scientist would refine and enhance their data and/or their labels incrementally and iteratively in order to reach the desired results.
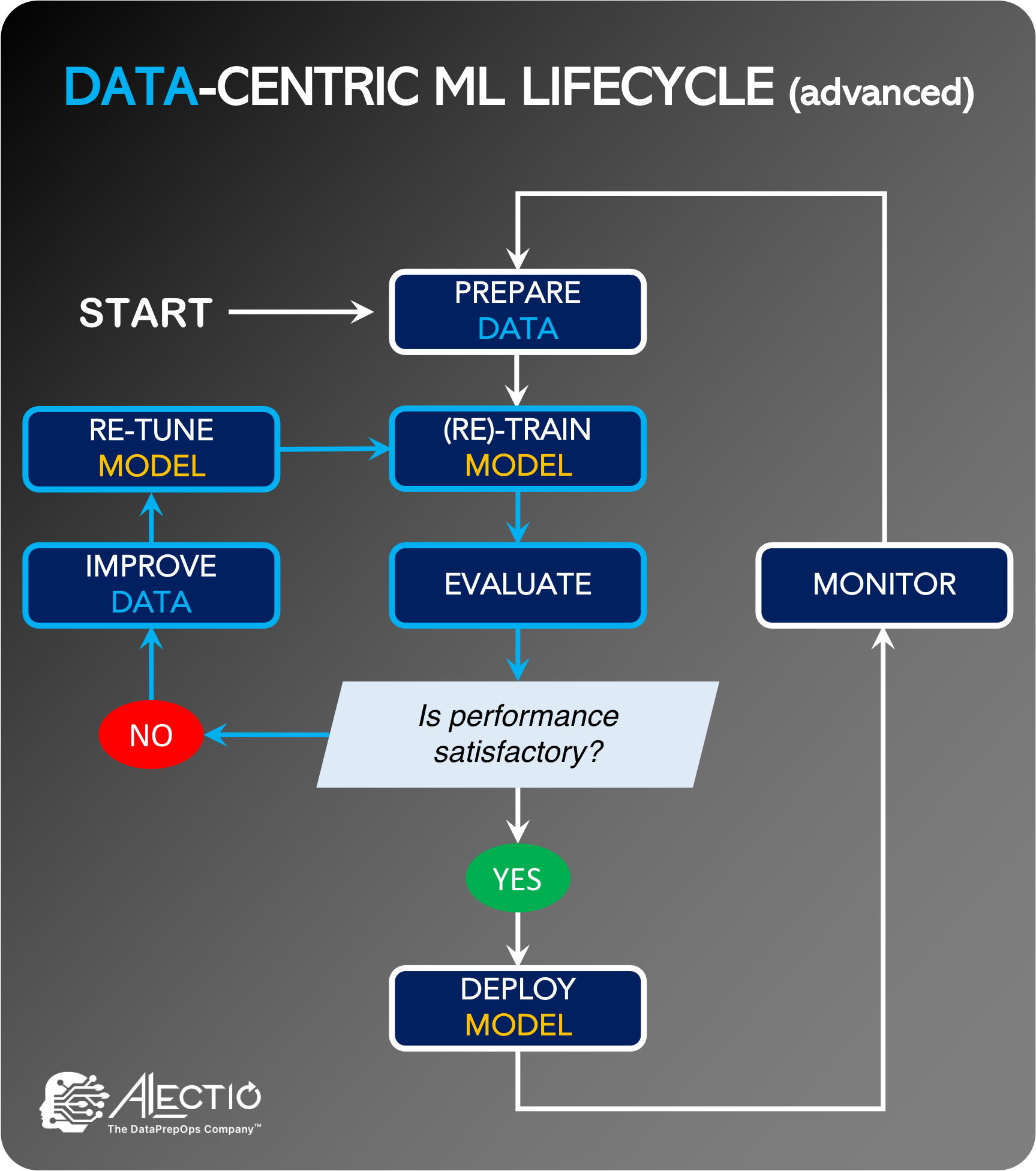
While the goal of Data-Centric AI is clear, ML scientists still have cursory understanding of best practices. Few ML scientists focus on the topic, even as areas of research emerge for the next generation of researchers to tackle.
While the near future might not contain a formal theory of Data-Centric Machine Learning to teach ML students, that does not mean that the data scientists of today cannot incorporate some of the key elements in their daily model development habits and processes.
As a start, here are the ways that a data scientist can incrementally improve their training data:
Adding more data
This can be achieved either by strategically collecting data, based on the observed weaknesses of the model, or by selecting data from a large pool of (usually raw) training data. Active learning, and other semi-supervised learning techniques that rely on synthetic labels are a natural choice for exercising this. Although, it is not without challenges (it might require more attention to controlling potential biases.)
Synthetizing more data
This is adding more data to correct issues in the model. But this time, by relying on the generation of synthetic data made specifically to boost the model’s performance. A couple examples include adversarial data contamination (also known as data poisoning) or active synthetic data generation (an approach meant to actively generate more impactful data to steepen the model’s learning curve.)
Removing data
While increasing the size of the dataset incrementally is the most common take on Data-Centric AI, reducing it is an equally valid approach that is unfortunately overlooked. While flawed, there is a universal belief that the more data, the better. But with dark and ROT data on the rise, dropping records from an unsatisfactory dataset might just be the best approach to addressing pollution in large datasets. As it turns out, the elimination of data might just be the Data-Centric way to address catastrophic forgetting in deep learning models.
Modifying data
There are times it might be impossible to add data, because collecting, scraping or generating more data might be too expensive, unfeasible or impractical. The same can be said about removing data, as it can be sparse to begin with. Even under those circumstances, data scientists still have options to operate with a Data-Centric mindset. An example would be to modify the records that are present in their dataset. Data augmentation (the process of slightly distorting data by applying transforms on the inputs) is a popular technique used by computer vision experts. It is often used when working with inadequate data, but rarely utilized to iteratively improve a dataset, even though data augmentation is an excellent technique to incorporate into a Data-Centric ML pipeline.

Improving / fixing the labels
Having great data gets you nowhere if your labels are faulty; that’s the core message of any labeling company out there. It might be the emergence of the majority of issues that might occur to your data. If most pickup trucks in an autonomous driving dataset are accidentally annotated as cars rather than trucks, there is little that can be done to fix the model, apart from starting the labeling process all over. Letting humans identify and fix faulty labels (contrary to popular perception, it can be originally generated either by a human or an AI) on the fly is what Human-in-the-Loop is all about. The process of letting humans fix bad labels has drawn so much interest from academia and the tech industry, that it eventually developed into an entire branch of Machine Learning, with a massive variety of different workflows allowing human and/or machine feedback into the process.
Ultimately, the core tenant of Data-Centric AI needs to be popularized: improving the data is just as viable a method to boost model performance as model tuning. It will also give you a better bang for the buck.
Our team at Alectio certainly hopes that you will give this idea a fair shake, and if you ever find yourself wanting to give it a try, we would be happy to help!
**********



0 Comments
Trackbacks/Pingbacks