
The Machine Learning field is full of buzz: deep learning, LSTMs, generative adversarial networks; the list keeps going on and on and on. Some of the most promising concepts, though, stand at the other end of the spectrum. Active learning has to be one of the top concepts on that list. This is very unfortunate because active learning is one of the most critically needed concepts in Machine Learning in a day and age when Big Data and ever-larger models (for example GPT-3 and Google’s new trillion-parameter language model) are making the process of training a model slow, tricky, and expensive.
What is active learning exactly? We’ve explained the details elsewhere, but put simply: active learning is a semi-supervised learning process (which means that only a fraction of the records are being labeled) which consists of going back and forth between model training phases and inference phases designed to “discover” the most useful data. With active learning, instead of injecting the entire training dataset all at once into the model, you start with a subset which you label and use for training a first version of the model, and you then use that model to infer on the rest of the training set (the part that’s still unlabeled) in order to select the next subset that seems most beneficial.
Active learning is an elegant solution to a lot of the most pervasive issues in ML today. If you can use it for your problem, we think you should. and will go as far as to say that not using it every time you can is a mistake. We couldn’t agree more. And yet, active learning is both rarely used in the industry and commonly misunderstood (many people confuse it with online learning, or even believe active learning is the term used to refer to the fact that most models need to be refreshed, updated, and retrained on a regular basis).
This article is intended to explain why – and also, to help you actually integrate active learning in practice into your ML lifecycle.
#1 – Active Learning isn’t part of ML curricula
If you ever check the profile of some of the most senior machine learning scientists on the market, you will find a lot of ex-mathematicians or applied scientists. As a reconverted particle physicist myself, I’d like to tell you that it’s because applied scientists make the best ML experts (that’s probably true anyway but let’s keep going).
However, there is a simple explanation to that: until recently, very few universities used to offer courses on machine learning, and hence, a lot of people were self-taught or learned how to use ML in the context of other disciplines (for example, I was one of the first people to use a neural network to select a specific type of particle decay within a large dataset).
Nowadays though, more and more curricula offer machine learning training. However, that training usually covers the basics in-depth, and sometimes fails to account for some of the key skills that students will need in practice when they get their first job. For instance, there is virtually no mention of the concept of data labeling in machine learning courses at the top US universities. Active learning, too, is missing from the curriculum. This fact sadly also tends to perpetuate the myth that more data equals better models.
#2 – Active Learning, just like Deep Learning, requires tuning
People often refer to active learning as if there was just one way of doing it. That is not the case. As explained in the brief introduction above, active learning is all about the dynamic sampling of a training dataset, where you “explore” the dataset in order to identify (step by step) the most promising records.
The big question, of course, is to know how this exploration should be done, including how many records should be selected at each loop, and what the selection strategy (called a querying strategy) should be.
There are countless ways of doing such a selection. With the “vanilla” way of doing active learning, that selection strategy is to use the output of the inference step to look for the records with the highest uncertainty, for example by using the confidence level as a proxy (least confidence = highest uncertainty, and hence, supposedly, the most useful data). Yet, there are many other ways to make that selection, including advanced techniques such as looking at the evolution of activation functions of the model, forgetfulness, etc., and identifying in a finite amount of time with a finite amount of resources which querying strategy is the best one is tantamount to tuning a deep learning model from scratch.
The simple fact is that many assume AL is synonymous with simpler selection strategies that can definitely turn people off from experimenting with it.
#3 – Active Learning isn’t dark magic/silver bullet
Active learning does work in many cases and offers a lot of promise to the ML community. However, literature reports that in about 10% of the cases, the results of an active learning process can lead to worse results than supervised learning.
This is in part because finding the right querying strategy and the right loop size isn’t trivial. But there is also another reason: active learning isn’t magic. If the data you collected doesn’t contain the information that your model needs in order to reach the accuracy you desire, active learning will not help you.
That’s because the process is designed to identify useless records which are not likely to move the needle during the training process; such records are typically either records containing redundant information (which doesn’t necessarily mean duplicate records), or irrelevant one (think of a case where you want to train a facial recognition algorithm, and one of the records doesn’t contain a person). The good news is that if your dataset is too small or isn’t sufficiently dense in information, your model will show signs of being data-starved with its learning curve (see below).
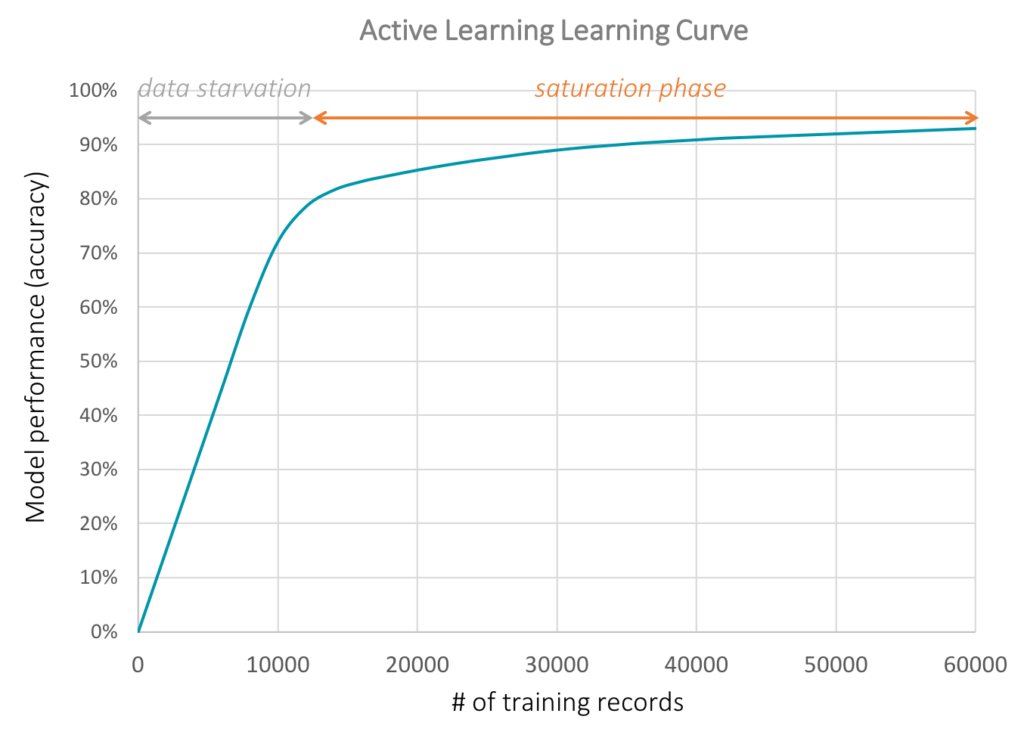
Figure 1: A data-starved model will display continued learning as more data is added like it is the case here for the first 10,000 records. During this phase, the model is still finding novel information in new records, and it is unlikely that an active learning process will find redundant information (it might still find irrelevant data though). After that stage, the model enters a saturation phase with diminishing returns.
#4 – “Regular” active learning is actually a rule-based algorithm
The “vanilla” active learning processes we discussed in section 2 are typically naively simple. The least confidence querying strategy, for example, prescribes that at each loop, you pick solely the N records that were inferred with the lowest confidence (typically, N is pre-determined prior to the beginning of the process) since low confidence is usually believed to be a good proxy for interestingness. In other words, the selection is based on a predetermined, static rule.
If that didn’t sound like a bad idea already, let’s add here that there is still very little tribal knowledge about the best way to choose such a rule. The key here is to recognize that the right way to think about the selection process, is to consider it as a machine learning problem, where instead of hard-coding and predetermining a querying strategy, we could use a model that could be trained and tuned based on the meta-data generated during those successive training processes (the active learning “loops”).
This is of course easier said than done, because who said machine learning, says feature selection, potential overfitting, potential biases, etc. At Alectio, we think of the selection process both as supervised learning and a reinforcement learning problem, and while it is still an active area of research, we’ve already seen a lot of successes and are usually able to overperform most vanilla querying strategies without the need to manually try each.
#5 – “Regular” active learning is solely focused on injecting novelty
One of the underlying assumptions behind most common querying strategies is that high uncertainty implies impactfulness on the training process. Essentially: if the model makes a prediction with high uncertainty, adding that record to the training set has to help.
There are two reasons why this might turn out to be inaccurate. First, if we are dealing with corrupted data or problematic data (imagine you work with English documents and that some documents in german accidentally made it into your training set), then while you will get a low confidence for those records, the last thing you’d want to do it add those examples in your training set.
The second reason is forcing only novel records (which will be the case if you select high uncertainty data), you are at risk to push the model into a state of accidental forgetting. The result will be that the model will eventually learn the difficult corner cases but fail with the regular examples. This is yet another reason why the querying strategy has to be carefully crafted and optimized for each model individually.
#6 – Active Learning can be computationally greedy
Active learning was originally invented to help reduce the labeling costs, and/or to address the fact that in some cases, data annotation has to be done by experts, such as doctors (in healthcare), lawyers (in legal tech), or geophysicists (in the oil industry), experts who are often in low supply.
However, while researchers usually measure their success with active learning by looking at the reduction in the amount of data that required labeling, academics often forget that at the very core of the active learning process lies a fundamental tradeoff between the number of labels and the amount of computation. That’s because active learning requires successive re-training of the model with increasingly large datasets, which often leads to a quadratic relationship between computation and the number of loops involved (see graph below). This means that in practice, it only makes sense to use active learning if the savings made on the labeling side overcome the increase in computation.
It goes without saying as well that, being incremental in nature, it takes more time to train a model with active learning, and savings in data labeling often doesn’t justify a dramatic increase in training time, especially if that model is already in production and needs to be retrained on a regular basis.
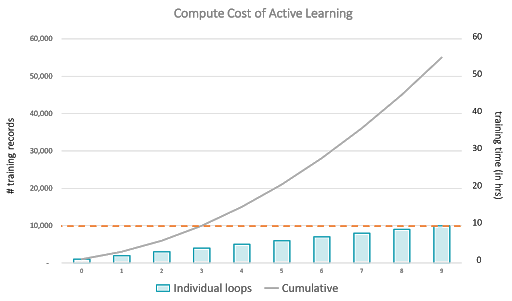
Figure 2: Because active learning typically requires retraining the model with an increasingly large amount of training data at each loop, the relationship between the amount of training data and the amount of computing resources is quadratic. In other words: while active learning helps you save on data labeling, it is not a cheap process.
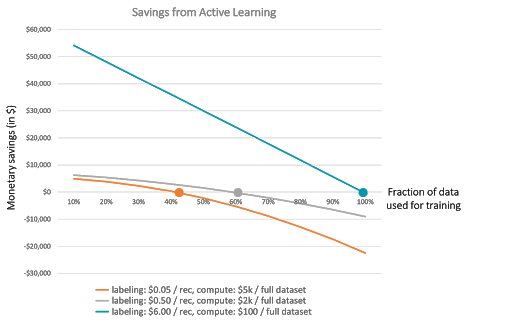
Figure 3: In order to save money with active learning, we need to compute the sum of the amount of money spent on labeling and on compute, and evaluate how that sum compares to what we would have paid without active learning: Active learning is a trade-off between labeling costs and training costs (not mentioning training time!). If the model is very complex and requires a lot of computing power, it might actually not be worth it to use active learning in practice, even if research papers fail to mention it. Here, the orange curve shows us a case where labeling is cheap compared to computation, and a compression of more than 60% would be necessary for active learning to make sense.
#7 – The current labeling market isn’t adapted to active learning
Computational greediness is unfortunately not the only consequence of the incrementality of the active learning process: the need to have data labeled in batches instead of all at once is also a major reason why many companies don’t see active learning as a practical option for them.
Most labeling companies out there offer great services if you need to get a lot of data labeled all at once, but they might not be as helpful if what you need is to send frequent data batches of smaller size which you need to get annotated quickly. The labeling industry is built for scale, not for speed, and that’s a problem if you plan to use active learning. Luckily, we have the perfect solution to that: a labeling marketplace designed for speed and agility, with partners who guarantee to get small batches of data labeled in hours as opposed to weeks or even months.
#8 – Active learning is Ops-heavy
Over the past years, the industry has learned the hard way that building machine learning products wasn’t simply about building fantastic models; models also need to be deployed, versioned, maintained in production, and often retrained on a regular basis.
This realization has led to the booming of a new discipline: MLOps. And MLOps isn’t easy, to put it mildly. Imagine now that, when using active learning, you need to orchestrate meticulous successions of alternating phases of training, inference, and selection. You will need to version not only each model but each loop within this model. You will need to track which data has been labeled, which means that you will need to version the labels as well. In fact, at Alectio, we don’t solely use forward-looking active learning, where the goal is to identify useful batches among a pool of unlabeled data, but we also use each loop as an opportunity to diagnose potential mislabeled instances.
Basically, active learning is not solely a challenge to the ML scientist, but also to the ML engineer responsible for the data pipelines. Today, while many companies offer MLOps solutions for supervised learning, none is offering support for active learning.
#9 – Done wrong, active learning can bias your training process
A common fear among first-time users of active learning is the prospect of generating biases. This is absolutely a legitimate concern for several reasons.
First, the initialization of an active learning process usually involves random sampling, which means that occasionally, one might get unlucky and get the process going on the wrong foot. One way of solving this––which we are using at Alectio––is to closely monitor the learning curve at the early stage and abort and restart the process if the initial sample appears to be problematic. However, determining that there is indeed a problem usually requires more than one metric and can be pretty complicated.
Another trick is to run multiple versions of the first loop before picking the most promising initialization, which is reminiscent of a simulated annealing process. But that isn’t even the main reason for potential biases. Think, for example, of what could happen if incorrect labels were to make it into the dataset. One of the biggest flaws of the typical active learning process is indeed the underlying assumption that the labels have to be correct – which is why attempting to identify problematic labels within the selected data (which has already been used for training) is almost a requirement to run a flawless Active Learning process.
***
All of these reasons explain why many ML experts are not leveraging active learning for their machine learning projects, even though it offers many benefits both from an operational and a performance perspective. Sadly, many among the few people familiar with active learning tend to give up as they tend to interpret their lack of success as a sign that active learning can’t be used for their use case, or even that active learning doesn’t work at all. Active learning does work. Yet, just like deep learning, it requires some adjustment and comes with a learning curve.
In the end, it’s easy to think of it like this: there’s no one single thing that’s “active learning.” It isn’t an algorithm, but a process that requires it to be developed and tuned properly. It’s a process that requires a solid and efficient labeling process that you can trust. It’s a process that requires the proper instrumentation, engineering processes, monitoring, and versioning systems. It’s a process that can easily go wrong and create more problems than it solves. And while the concepts in active learning are fairly easy to understand, it still requires expertise. This is exactly the reason why the Alectio platform exists in the first place.



0 Comments
Trackbacks/Pingbacks